


2018 School Spending Survey Report
Library of Congress Trains Machine Learning Tool with Crowdsourcing
The LC Labs department of the Library of Congress recently published a comprehensive report on its Humans-in-the-Loop initiative, which crowdsourced volunteers to train a machine learning (ML) tool to extract structured data from one of the library’s digital collections. It also explored the intersection of crowdsourcing and ML algorithms more broadly. The project resulted in a framework that will inform future crowdsourcing and data enrichment projects at LC, and the report offers other libraries and cultural heritage institutions insights and advice for developing engaging, ethical, and useful crowdsourcing projects of their own.
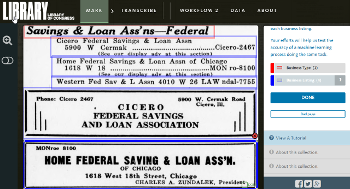 |
The crowdsourcing prototype developed by AVP featuring segmentation of business types and business listings from Yellow Pages in the U.S. Telephone Directories collection. Image captured by Meghan Ferriter |
The LC Labs department of the Library of Congress recently published a comprehensive report on its Humans-in-the-Loop (HITL) initiative, which crowdsourced volunteers to train a machine learning (ML) tool to extract structured data from one of the library’s digital collections. It also explored the intersection of crowdsourcing and ML algorithms more broadly. The project resulted in a framework that will inform future crowdsourcing and data enrichment projects at LC, and the report offers other libraries and cultural heritage institutions insights and advice for developing engaging, ethical, and useful crowdsourcing projects of their own.
The LC Labs staff worked with subject matter experts and partners from data solutions provider AVP to develop the program, aiming “to model, test, and evaluate various relationships and interactions between crowdsourcing and ML methods in ways that will expand the Library’s existing efforts to ethically enhance usability, discovery, and user engagement around digital collections,” according to the report.
HITL “is the next step, coming from a large body of work in exploring crowdsourcing and also exploring machine learning in library contexts,” Meghan Ferriter, senior innovation specialist for the Library of Congress, LC Labs, told LJ.
INNOVATION LAB
Prior projects at LC Labs include ML experiments such as Citizen DJ and Newspaper Navigator, crowdsourcing projects such as Beyond Words and By the People, events such as the 2019 Machine Learning + Libraries Summit, and collaborations on projects and white papers including Digital Libraries, Intelligent Data Analytics, and Augmented Description.
“Our work is to experiment on behalf of the [Library of Congress’s] Digital Strategy, and the Digital Strategy’s three goals are throwing open the ‘treasure chest’ [of the Library’s holdings], connecting with the public and with American audiences, and investing in our future,” Ferriter said. “We’re always trying to triangulate those three goals in our work.”
Ferriter explained that LC Labs’ earlier work had set the stage for an experiment exploring crowdsourcing and ML together. The Library of Congress’s “treasure chest” of digital content is vast, and ML tools can help scale metadata creation to levels that would be impossible for small teams of subject matter experts alone. However, human expertise is essential for training ML algorithms and validating workflows, and commercial ML tools used for tasks such as image or text analysis had proven to be problematic in past projects. “When we tried to adopt off-the-shelf [ML] tools and products, or we tried to adopt a one-size-fits-all approach…we kept seeing that what has been created in the industry does not fit well in a cultural heritage context,” she said. “Maybe, at best, they obscure context.”
CROWDSOURCING HELP
So LC Labs set out to use crowdsourcing to refine an ML tool. The “HITL initiative deliverables included the design of an experimental prototype that serves as proof of concept for two human-in-the-loop workflows—one in which humans create training data for ML processes, and another where humans correct the output of ML processes,” the report states.
Since crowdsourcing relies on volunteer labor, and since ML tools can respond in unexpected ways to training, the team defined three central concepts that it would revisit and adhere to at each stage of the project’s collection selection, design, implementation, and presentation.
- Engaging: The collection should be interesting for volunteers to work with, and they should feel a personal connection or a sense of ownership of the content.
- Ethical: Data exposed from the collection must respect the privacy of collection subjects or creators, and any potential risks to users, collection creators, or subjects must be identified and mitigated.
- Useful: The project should model replicable selection process for human-in-the-loop projects, data generated from the collection should improve discoverability of that content, the content should be useful to library users, and the content must be free of permissions restrictions to enable broad use.
The idea of asking volunteers to work with an engaging and interesting collection to generate useful, discoverable content may seem like a self-evident plan for creating a crowdsourcing project. The emphasis on an ethical approach to working with historical collections may be less obvious. Ferriter explained that, in addition to ensuring privacy and identifying any risks a cultural heritage project might entail—such as the possibility of exposing volunteers to culturally insensitive or offensive content—ethics was inseparable from the other two concepts.
“Rather than thinking exclusively about our organizational needs, [we are] trying to think about ‘what is an equitable and reciprocal relationship that’s being established by asking people to engage in this way?’” Ferriter said. “We would want to think about from the very beginning ensuring that the types of data that would be emerging from this type of workflow would be available widely. That they wouldn’t be squirreled away, and that they would be used and useful. We wouldn’t want people to undertake work that would be wasteful of their time…. Making sure that the tasks that we are asking people to engage with…aren’t something that could be accomplished by a machine…. And consistently acknowledging and recognizing people’s contributions.”
DIALED IN
Following a nomination process to select a collection and a workshop to discuss the “potential risks and biases that might be introduced to human volunteers, end users, and collection creators or subjects through the specific tasks proposed for each goal,” four finalist collections were chosen for technical review. From those, AVP selected the U.S. Telephone Directory Collection—a popular collection of directories from 15 states spanning most of the 20th century that is frequently used by legal researchers and individuals researching genealogy and family histories, among others. The collection was already digitized from microfilm.
In addition to its usefulness, the collection “was chosen for its homogeneity in subject matter, layouts, fonts, and structure across most digitized items, which makes it a prime candidate for applying machine learning and other batch processes. The task of transforming digitized images into structured business listing data is complex enough that multiple types of machine processes could be tested, but not so complex that it could not be completed (for a small subset of pages) within the very limited prototype timeframe,” the report explains.
The next step involved determining what structured data the ML processes would extract. During the selection process, the team had listed use-case scenarios for the four finalists. Uses for the directory collection included genealogy research, which would involve searching the phone books by the names of individuals and businesses to help identify where a researcher’s family members had lived or worked; business owners who wanted to search historical business listings and ads to determine what types of businesses had previously operated at their address; historians who would want to group listings from a directory by type or industry to compare their prevalence in an area over time; and several more specific uses, such as special collections staff wanting to identify businesses owned by members of or serving underrepresented communities in a specific location and during a specific timeframe.
Although developing a data enrichment model for all of these use cases was beyond the capacity of the initial HITL project, “thinking big about possible collection enhancement helped the team design a flexible and extensible data model that would support additional future enrichment of the collection,” according to the report.
FOCUSED APPROACH
The team decided that, for the purposes of the HITL project, the ML tool would focus on generating structured business listing data. Following a few experiments, AVP designed a system in which the ML tool used the open-source computer vision programming library OpenCV to split up two-page images into individual pages and find boxed advertisements on each page using contour detection. It then used the open-source Tesseract optical character recognition (OCR) engine to identify business types, find business listings, and identify business groupings. A conditional random fields algorithm trained on human-generated examples was then used to identify entities within the business listings.
In order to train the ML tool, the team created a set of five tasks for volunteers on the crowdsourcing side of HITL. (A fork of the open-source Scribe platform maintained by the Utrecht University Digital Humanities Lab was used for the back-end of the crowdsourcing effort.) Volunteers identified segments of directory pages including business groupings, advertisements, and telephone tips; identified and classified business types and business listings; transcribed the text of different business types; identified and classified business listing entities; and transcribed the text of each entity.
IN THE LOOP
The full 97-page report on HITL details the challenges faced and resolved during each stage of HITL’s development and includes a comprehensive description of the user testing process the team used to create the interface design of the crowdsourcing platform. Key takeaways were that future HITL initiatives have the potential to maximize access to the Library of Congress’s digital content at scale, although these projects will require significant investment in staffing and resources. Approaches to HITL can be generalized, but each future project will require some tailoring—there won’t be a one-size-fits-all approach to building ML tools for different digital collections.
But as Ferriter noted, well-designed crowdsourcing projects benefit volunteers as well. “It’s very exciting, the potential—the possibility—that is inherent in collaboration,” Ferriter said. “One of my favorite things about the work on the LC Labs team is the opportunity to collaborate with our colleagues across the Library, but also people more widely in the field…. But one thing that I come back to again and again—and I’ve seen it firsthand—is that inviting people to participate in crowdsourcing projects or to develop literacies about the way information is stewarded and presented…those experiences can be transformational.”
Add Comment :-

Added To Cart
RELATED


RECOMMENDED


TECHNOLOGY

ALREADY A SUBSCRIBER? LOG IN
We are currently offering this content for free. Sign up now to activate your personal profile, where you can save articles for future viewing
ALREADY A SUBSCRIBER? LOG IN
Thank you for visiting.
We’ve noticed you are using a private browser. To continue, please log in or create an account.
